
Data Handling Using Pandas - Dataframes #3 - vol. 3
Customizing labels/ Changing index and column labels


Hello readers, in my previous story we learned about how to create empty dataframe, dataframe from list of dictionaries, dataframe from list of lists, dataframe from dictionary of lists, dataframe from dictionary of series with examples.
Now let's get started with a new thing i.e. Customizing labels/ Changing index and coloumn labels.
The index and columns parameters can be used to change the default row and column labels. Consider the dataframe given below,
Input:
import pandas as pd
a=[[1,"Amit"],[2,"Chetan"],[3,"Rajat"],[4,"Vimal"]]
b=pd.DataFrame(a)
print(b)
Output:
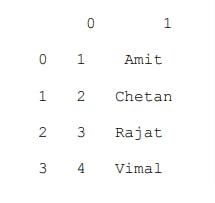
Now, suppose if we want to have “Roll no” and “Name” as the column labels and numbers from 1 to 4 as the row labels.
What will be our next step? So that we can name the column as "Roll No" and "Name"
Checkout the example below,
EXAMPLE 6:
Input:
import pandas as pd
a=[[1,"Amit"],[2,"Chetan"],[3,"Rajat"],[4,"Vimal"]]
b=pd.DataFrame(a, index=[1,2,3,4], columns=["Roll No.", "Name"])
print(b)
Output:
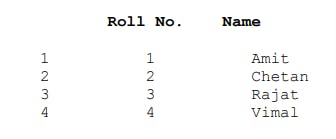
Let me explain it more deeply,
EXPLANATION:
Here you can see that using index parameter the row labels are changed to 1,2,3 & 4. Similarly using columns parameter the column labels are changed to "Roll No." and "Name".
One can easily change the default order of row labels to user defined row labels using the index parameter. It can be used to select only desired rows instead of all rows. Also, the columns parameter in the DataFrame() method can be used to change the sequence of DataFrame columns or to display only selected columns.
EXAMPLE 7:
Input:
import pandas as pd
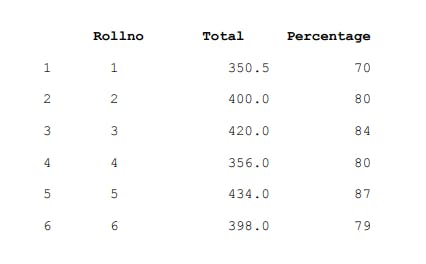
d2={"Rollno":pd.Series([1,2,3,4],index=[1,2,3,4]),
"Total":pd.Series([350.5,400,420],index=[1,2,4]),
"Percentage":pd.Series([70,80,84,80],index=[1,2,3,4])
}
df3=pd.DataFrame(d2)
print(df3)
Output:
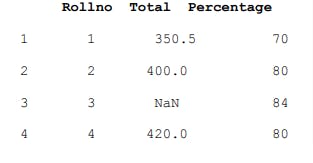
EXPLANATION:
Here, the dictionary keys are treated as column labels and the row labels are a union of all the series indexes passed to create the DataFrame. Every DataFrame column is a Series object.
Now, we will be creating dataframe from a dataframe object,
Didn't get it? Let me show you a fantastic example,
EXAMPLE 8:
Input:
df4=pd.DataFrame(d2, columns=["Rollno","Total"])
df4
Output:
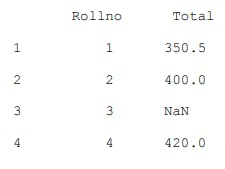
Here, only two columns Roll no and Total are there in df4. Therefore, all rows are displayed.
let's have a look on the below example,
EXAMPLE 9:
Input:
>>>df5=pd.DataFrame(d2, index=[1,2,3], columns=["Rollno","Percentage"])
>>>df5
Output:
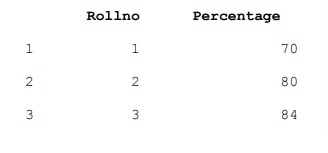
So here, in df5 dataframe only two columns Roll no. and Total are stored and displayed. Only rows with index values 1,2 and 3 are displayed.
DATAFRAME ATTRIBUTES
The dataframe attribute is defined as any information related to the dataframe
object such as size, datatype. etc. Below are some of the attributes about the
dataframe object. (Consider the dataframe df1 defined below for all the examples):
1. df1.size: Return an int representing the number of elements in given dataframe.
print(df1.size)
Output is 18
In this example how we get output as 18? you see how we get the output here (6 rows X 3 columns =18)
2. df1.shape: Return a tuple representing the dimensions of the DataFrame.
print(df1.shape)
Here we will get output as (6, 3).
3. df1.axes: Return a list representing the axes of the DataFrame.
print(df1.axes)
Output:

4. df1.ndim:
Return an int representing the number of axes / array dimensions
print(df1.ndim)
Here the output will be 2.
5. df1.columns:
The column labels of the DataFrame
print(df1.columns)
Output:

6. df1.values:
Return a Numpy representation of the DataFrame.
print(df1.values)
Output:

7. df1.empty:
Indicator whether DataFrame is empty
print(df1.empty)
Here the output will be False.
That's all for now reader. In next volume I will be sharing my insights over Row/Column Operations. Stay tuned for vol.4 🤞
If you haven't checked the whole series of Data Handling Using Pandas Dataframes also check out the other two volumes 👇